
DeepSeek:中国AI大模型产业的破局者与2025年的展望
 摘要:
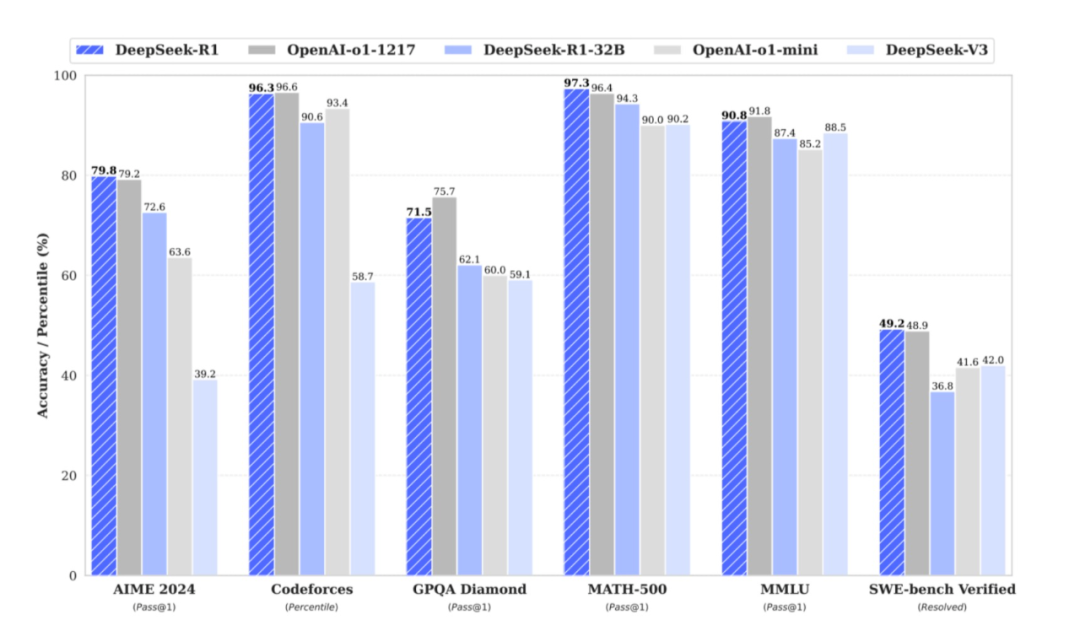
DeepSeek的横空出世,打破了AI大模型领域原有的游戏规则。它以极低的成本(参数规模仅为传统模型的十分之一),通过强化学习和模型蒸馏技术,在数学题解答等方面超越了GPT-4,并...
摘要:
DeepSeek的横空出世,打破了AI大模型领域原有的游戏规则。它以极低的成本(参数规模仅为传统模型的十分之一),通过强化学习和模型蒸馏技术,在数学题解答等方面超越了GPT-4,并... DeepSeek的横空出世,打破了AI大模型领域原有的游戏规则。它以极低的成本(参数规模仅为传统模型的十分之一),通过强化学习和模型蒸馏技术,在数学题解答等方面超越了GPT-4,并开源代码和API,引发了业界轰动。
DeepSeek的成功,主要体现在以下几个方面:
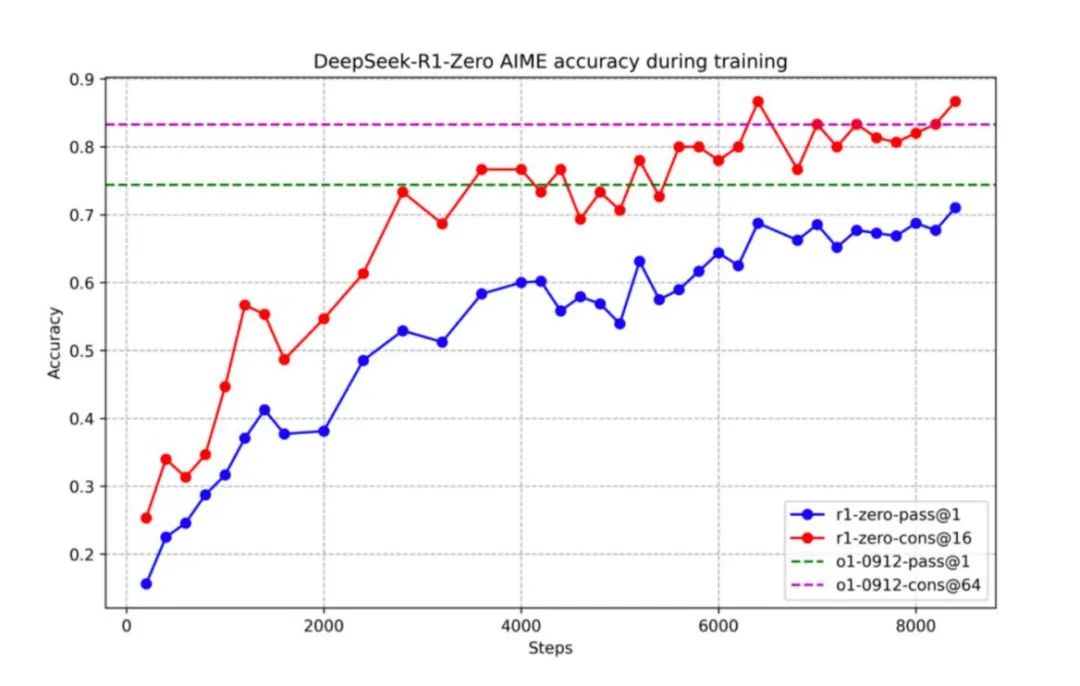
技术范式转变:低成本、高性能的模型成为可能。传统大模型训练成本高昂,DeepSeek通过纯强化学习和创新的奖励机制,大幅降低了数据准备成本和算力消耗,实现了“价廉物美”的模型效果,这对于中大型企业和小型科技公司来说都是利好消息,使他们能够以更低的成本部署大模型项目,并专注于数据治理和应用开发。
开源加速:垂直小模型时代来临。DeepSeek构建了跨维度知识蒸馏体系,将大型模型的推理能力“蒸馏”到小型模型中,在参数规模大幅缩减的情况下,性能反而提升,这将推动垂直领域的小模型发展,降低中小企业参与AI的门槛,使他们能够在特定行业中快速开发定制化AI应用,并成为垂直赛道的引领者。
效率与场景突破:端侧应用爆发。DeepSeek在模型压缩和推理效率方面的提升,使其能够在资源受限的边缘计算设备和实时决策场景中发挥作用,例如智能眼镜、金融交易等,推动端侧AI应用的爆发式增长。
生态变革:大厂炼模型,中小厂做应用。DeepSeek的开源和开放API,打破了巨头主导的“金字塔式”生态,形成大厂专注模型研发,中小厂专注应用开发的新模式,这将促进技术民主化、生态正循环和场景定制化,推动AI产业的可持续发展。
展望2025年,中国AI大模型产业将更加注重商业落地,研发方向将聚焦于强化学习和模型蒸馏技术,商业化路径将优先布局B端市场,并积极构建生态联盟,打造一批“小而美”的行业模型,在特定领域形成对西方模型的局部优势。DeepSeek的出现,标志着中国AI产业正在迈向一个充满机遇和挑战的新时代,尽管挑战依然存在,但中国AI大模型产业的未来发展势头强劲,不可阻挡。




相关推荐
-
中海达(300177)资金博弈:主力撤退与散户接盘,营收增长难掩亏损,关注美债殖利率
-

职场续命?小熊养生壶2.0,收割焦虑的精致陷阱
-

业绩暴跌?别再无效努力!销售转化、客服售后,企业增长真相揭秘
-

畸形“谷子经济”:收割年轻人的“悦己”陷阱?效率革命?揭秘科技巨头主导的AI Agent中国“人造太阳”:能源突破还是资本狂欢?专注达“一药难求”:ADHD患者的困境与药物滥用商业航天:规模化生产背后的隐忧与挑战跨境支付:金融机构“出海”稳订单,谁主沉浮?脑机接口:马斯克的“疯狂”设想,是未来还是伦理危机?
-

警惕自我标签陷阱:低自我感是穿越周期、突破瓶颈的关键
-

AI家电大跃进:智能革命还是圈钱游戏?
-
**幣圈KOL現形記:有人真耕耘,有人磨刀霍霍向韭菜!**
-

黄金惊天逆转!3016抄底狂赚,杜康再曝暴富密码!
还没有评论,来说两句吧...